ARI Architecture
Inference
ARI’s relation inference architecture is a layered cascade of deterministic logic and probabilistic models, combining symbolic structure with learned similarity to infer high-quality mappings between schemas.
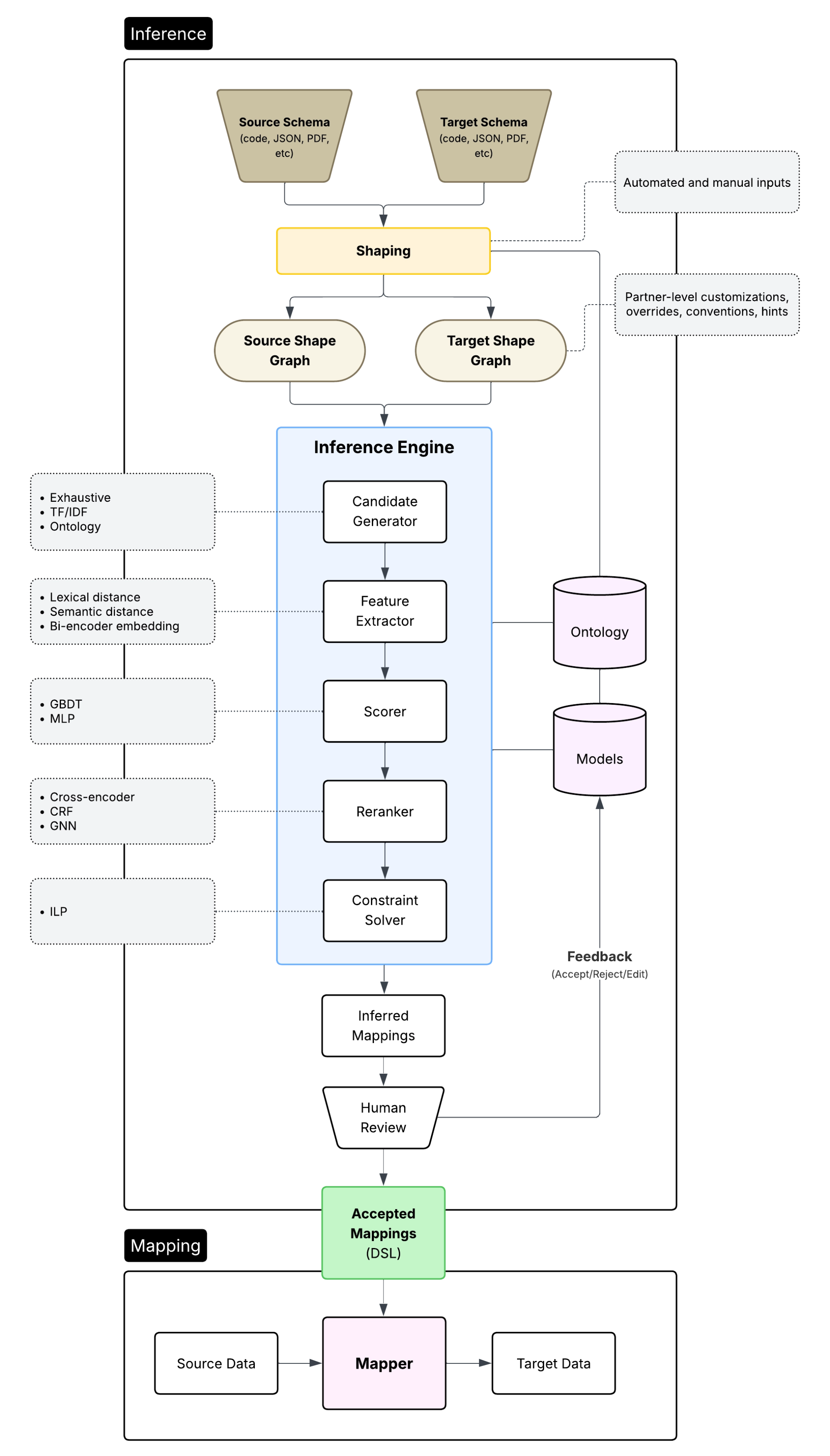
Starting from heterogeneous source and target schemas, ARI first normalizes structure into shape graphs (shaping). It then generates candidate correspondences, computes rich lexical, semantic, and structural features, and scores them using learned models. Higher-order models, such as cross-encoders, CRFs, and graph-based methods, encourage structural consistency, while a constraint solver produces globally optimal and consistent mappings. Human feedback and ontology signals continuously refine both the models and the resulting mappings.
Training datasets
ARI trains a unified model over four structured layers of training data, progressing through pretraining, supervised alignment, and fine-tuning. Each dataset is incorporated with controlled weighting, scheduling, and task-specific objectives.
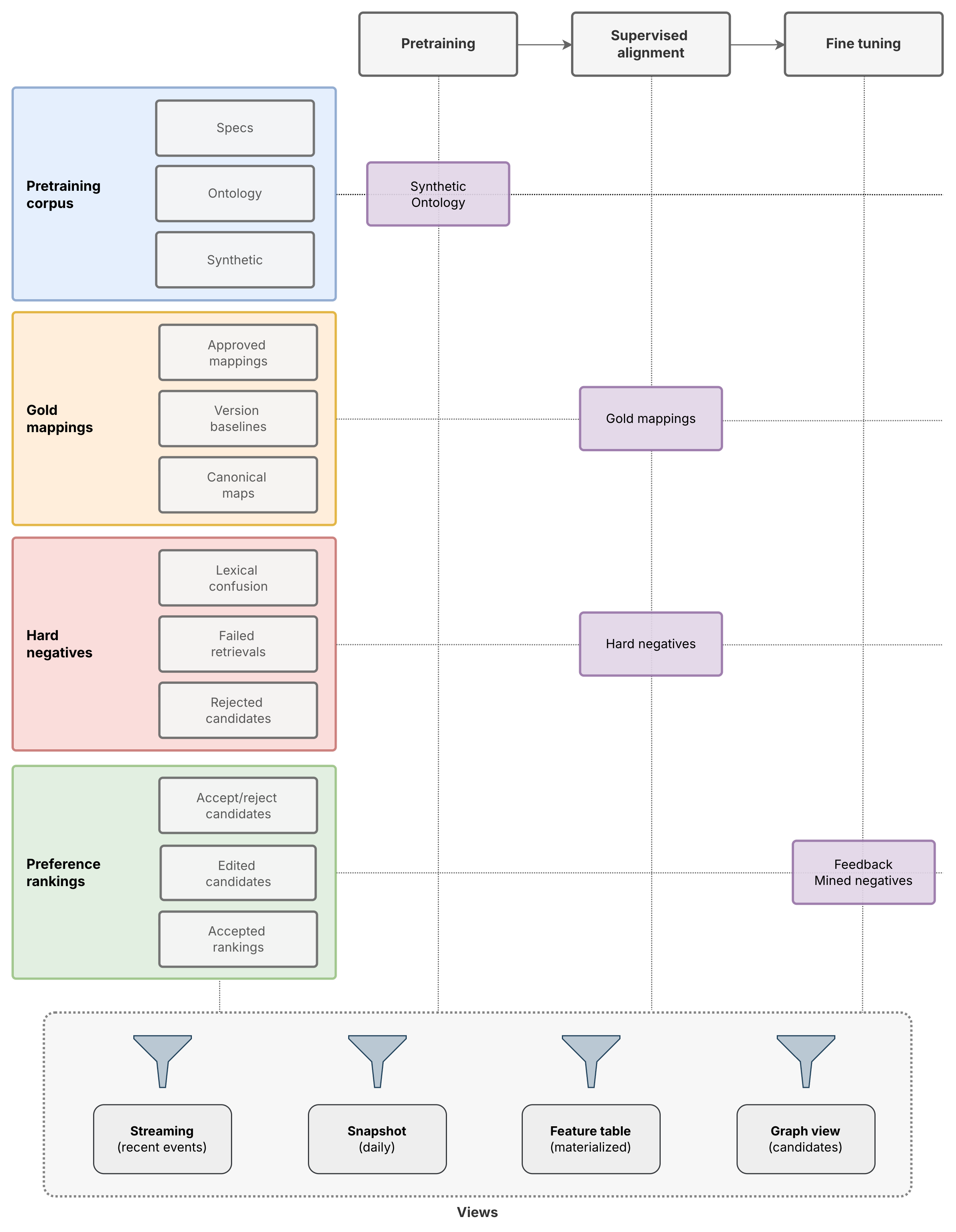
Pretraining establishes structural and semantic priors using specifications, ontologies, and synthetic data. Supervised alignment refines the model using verified mappings and curated hard negatives. Fine-tuning incorporates human feedback and mined negatives to align ranking behavior with real-world usage. Across all stages, ARI dynamically balances data sources and objectives to ensure both recall and precision, while maintaining global structural consistency.
Training data flow
Training data from mappings, user feedback, and synthetic generation is unified into a canonical stream of training examples. These examples are normalized, enriched with lightweight features, and projected into model-specific datasets for each component of the inference stack.
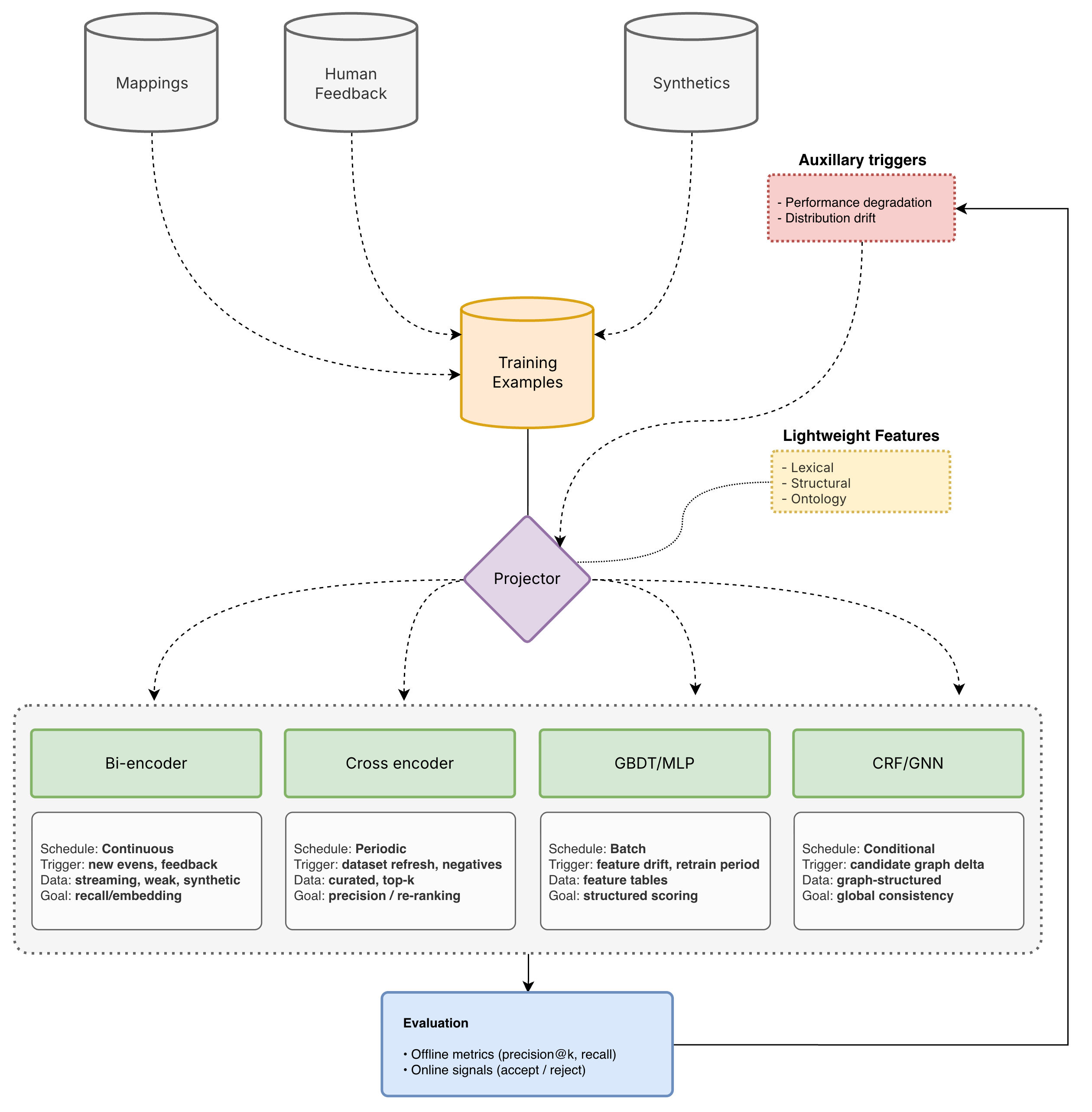
All training signals, whether derived from production mappings, human feedback, or synthetic generation, are first captured as structured training examples. This representation provides a consistent foundation for feature computation, including lexical, structural, ontological, and embedding-based signals. A projection layer then transforms these examples into the specific formats required by each model, enabling a single data pipeline to support heterogeneous learning objectives across the system.
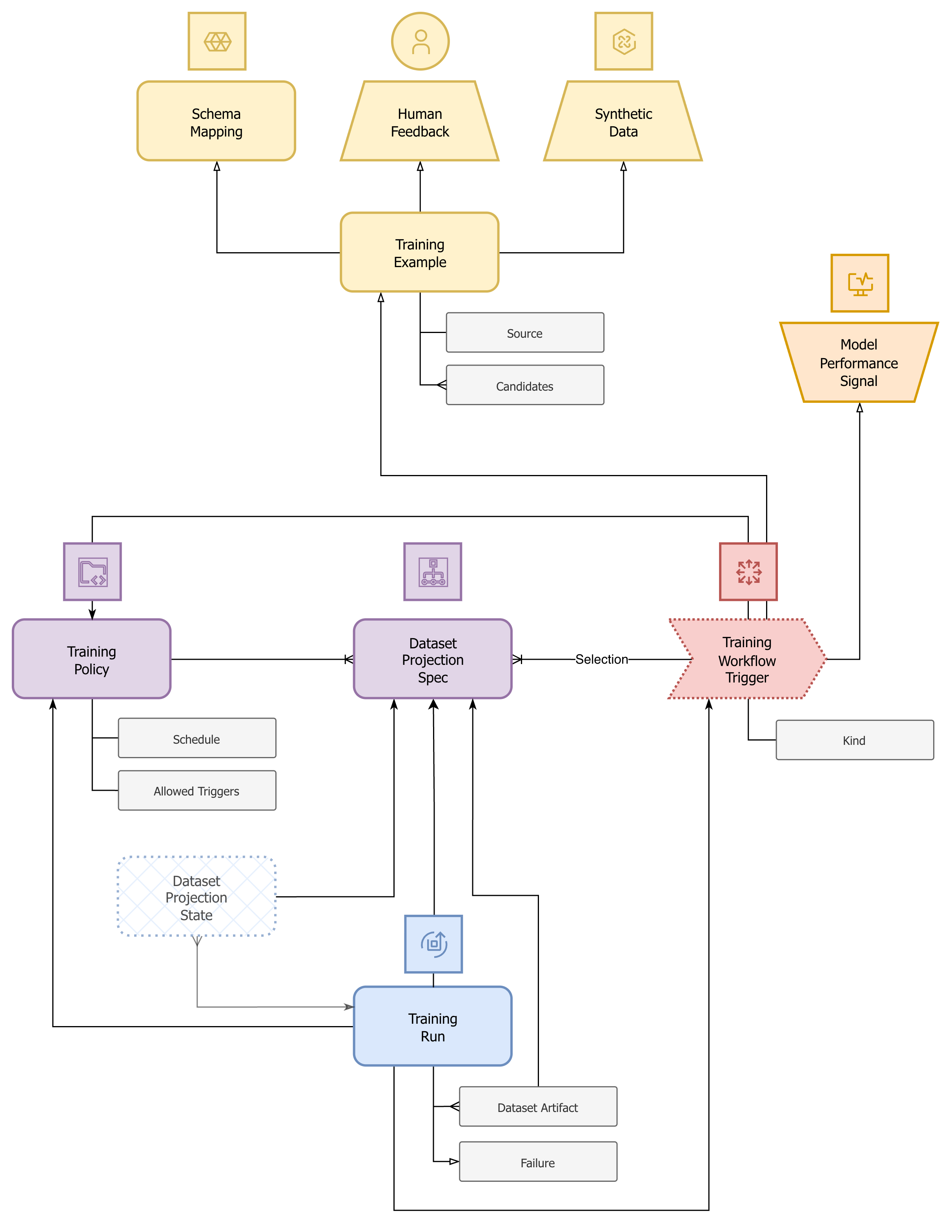
Training data model
The following diagram depicts the internal data model of the ARI training system.